阿里巴巴二面总结
二面面试官澄观,一看就很牛逼的样子,年龄也比一面的易统大一些,拿着我的简历,顺手拿了几个零食把我带到大厅,开始面试
1.你擅长什么?
我去,突出一个防不胜防,没有自我介绍,也不问项目,简历扫了一眼,扔一边。
这个问题不好答,我怕给自己挖一个坑,我就说linux用的还行,他说哪方面,我说系统使用方面,常用命令比较熟,他就问了一个问题,把一个文件夹里的.cpp文件中的BUPT换成alibaba,怎么实现?
sed -i “s/BUPT/alibaba/g” ./*.cpp
个人感觉这个问题就是坑啊,如果不是特别擅长,很容易被问住,好比让你在简历上选填你精通什么,然后问到你挂。
2.学生期间有什么可以展示的,不限技术
随意发挥
3.有用过多线程或者多进程么?在什么情况下用的?两者有什么区别
项目中有个监听线程,监听到3G网卡掉线,自动重连。
多线程好处:节约资源,并发快
多进程好处:安全,即使子进程挂了,父进程不会挂
多线程缺点:不安全,一个线程挂掉,整个进程挂了
多进程缺点:资源占用比较多,并发性不如线程
4.apache知道吗?看过源码吗?是多进程还是多线程的?http请求方法有哪些?服务器怎么知道用户登陆过?
知道,没看过,猜测是多进程的,GET,POST,(其余不常用,没怎么记,面试官貌似不满意)。
通过sessionid,用户请求时,服务器生成一个sessionid传给客户端,客户端用cookie保存sessionid,然后登陆的时候通过cookie把sessionid再发送给服务端。(大致这个意思,面试官大致满意)
5.二叉树求深度,不准递归,树是只读的
我的思路:用队列按层遍历,每一层加一,面试官说:你怎么知道这一层遍历完了?这里想了很久,说再用一个栈保存结果,栈为空的时候,这层完了,此时加一,面试官说:行是行,但浪费空间。
6.求一千亿个数的中位数,这些数无序
我的思路:hash%1000,分成小文件,求出小文件的最大和最小值,然后按照这个区间,使得这1000个小文件按照顺序排列,中位数在中间的小文件里,面试官说:不一定。发现是的,我说那我记录每个文件的个数,根据这个元素个数定位到小文件,对这个小文件排序,根据偏移量,找到中位数,面试官说对。
总结:深入再深入,必须能有一样能征服面试官的,要有亮点,这点我还得加强,本来想说项目,直接被无视。算法题注定是难的,千万别放弃,展示出想要解决他的勇气,可以问面试官要提示,互动的解决这个问题,一旦放弃,这轮面试也就挂了。
关于session和cookie
为什么会有cookie和session呢,大家都知道,http是无状态的协议(无状态是指,当浏览器发送请求给服务器的时候,服务器响应,但是同一个浏览器再发送请求给服务器的时候,他会响应,但是他不知道你就是刚才那个浏览器,简单地说,就是服务器不会去记得你,所以是无状态协议。),客户每次读取web页面时,服务器都打开新的会话,而且服务器也不会自动维护客户的上下文信息,那么要怎么才能实现网上商店中的购物车呢?
session就是一种保存上下文信息的机制,它是针对每一个用户的,变量的值保存在服务器端,通过SessionID来区分不同的客户,session是以cookie或URL重写为基础的,默认使用cookie来实现,系统会创造一个名为JSESSIONID的输出cookie,我们叫做session cookie,以区别persistent cookies,也就是我们通常所说的cookie,注意session cookie是存储于浏览器内存中的,并不是写到硬盘上的,这也就是我们刚才看到的JSESSIONID,我们通常情是看不到JSESSIONID的,但是当我们把浏览器的cookie禁止后,WEB服务器会采用URL重写的方式传递Sessionid,我们就可以在地址栏看到sessionid=KWJHUG6JJM65HS2K6之类的字符串。还有一种技术叫做表单隐藏字段。就是服务器会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把sessionid传递回服务器。
Cookie是通过客户端保持状态的解决方案。从定义上来说,Cookie就是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息。让我们说得更具体一些:当用户使用浏览器访问一个支持Cookie的网站的时候,用户会提供包括用户名在内的个人信息并且提交至服务器;接着,服务器在向客户端回传相应的超文本的同时也会发回这些个人信息,当然这些信息并不是存放在HTTP响应体(Response Body)中的,而是存放于HTTP响应头(Response Header);当客户端浏览器接收到来自服务器的响应之后,浏览器会将这些信息存放在一个统一的位置,对于Windows操作系统而言,我们可以从:[系统盘]:\Documents and Settings[用户名]\Cookies目录中找到存储的Cookie;自此,客户端再向服务器发送请求的时候,都会把相应的Cookie再次发回至服务器。而这次,Cookie信息则存放在HTTP请求头(Request Header)了。有了Cookie这样的技术实现,服务器在接收到来自客户端浏览器的请求之后,就能够通过分析存放于请求头的Cookie得到客户端特有的信息,从而动态生成与该客户端相对应的内容。通常,我们可以从很多网站的登录界面中看到“请记住我”这样的选项,如果你勾选了它之后再登录,那么在下一次访问该网站的时候就不需要进行重复而繁琐的登录动作了,而这个功能就是通过Cookie实现的。
**关于二叉树求深度 **
思路:先层次遍历一遍找出最后一个节点,然后目的变为求这个节点的深度。然后我们用循环一层一层找到它的上一层,找到一次,深度加1,最终可以得到二叉树的深度。不需要栈了。
例如下面的树:
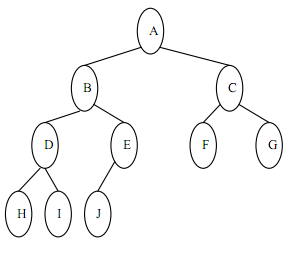
首先按层遍历获得最后一个元素J,然后从根再次按层遍历找到他的父节点E,此时深度+1,再从头按层遍历找到E的父节点B,此时深度加1,直到根节点为止
**关于1000亿个数的中位数 **
我的那种hash%1000的分割法有点问题,因为整数是有范围的,可按照整数范围分割文件,这样就不需要对每个文件排序,然后根据index偏移量找到小文件,只需对这个文件进行排序,取偏移量的数即可
blog comments powered by Disqus